Neural networks are an important tool for data scientists. They allow computers to learn from large amounts of data in an automated way, without being explicitly programmed. Different neural network architectures process data in various ways to extract useful insights. This blog post will explore some common neural network types and how they work. It will discuss multilayer perceptrons, convolutional neural networks and recurrent neural networks. Understanding these architectures is important for anyone interested in data science. This post will break down the key concepts in a simple way. Whether you are new to data science or looking to enhance your skills, this overview can help you gain a solid foundation. I hope you find it useful as you continue your Online Data Science Certification.
Introduction to Neural Networks and Deep Learning
Neural networks have revolutionized the field of artificial intelligence, particularly in areas such as image recognition, natural language processing, and speech recognition. These networks are inspired by the structure of the human brain, consisting of interconnected nodes, or neurons, that process information. Deep learning, a subset of machine learning, utilizes neural networks with multiple layers to extract higher-level features from raw data, enabling complex pattern recognition and decision-making.
The Basics of Neural Network Architecture
At its core, a neural network consists of an input layer, hidden layers, and an output layer. The input layer receives raw data, such as pixels from an image, while the hidden layers process this information through weighted connections. Each neuron in a hidden layer applies an activation function to the weighted sum of its inputs, introducing non-linearity to the network. The output layer produces the final prediction or classification based on the processed data.
Feedforward Neural Networks: A Fundamental Model
Feedforward neural networks, also known as multi-layer perceptrons (MLPs), are the simplest form of neural network architecture. These networks pass information in one direction, from the input layer to the output layer, without any loops or cycles. Feedforward networks are well-suited for tasks such as image classification and regression, where the input data can be represented as a fixed-length vector.
Convolutional Neural Networks (CNNs): Unveiling Image Processing
Convolutional neural networks (CNNs) are specialized neural networks designed for processing grid-like data, such as images. CNNs use convolutional layers to extract features from the input image, such as edges, textures, and shapes. These features are then passed through pooling layers to reduce dimensionality and improve computational efficiency. CNNs have achieved remarkable success in image recognition tasks, surpassing human performance in some cases.
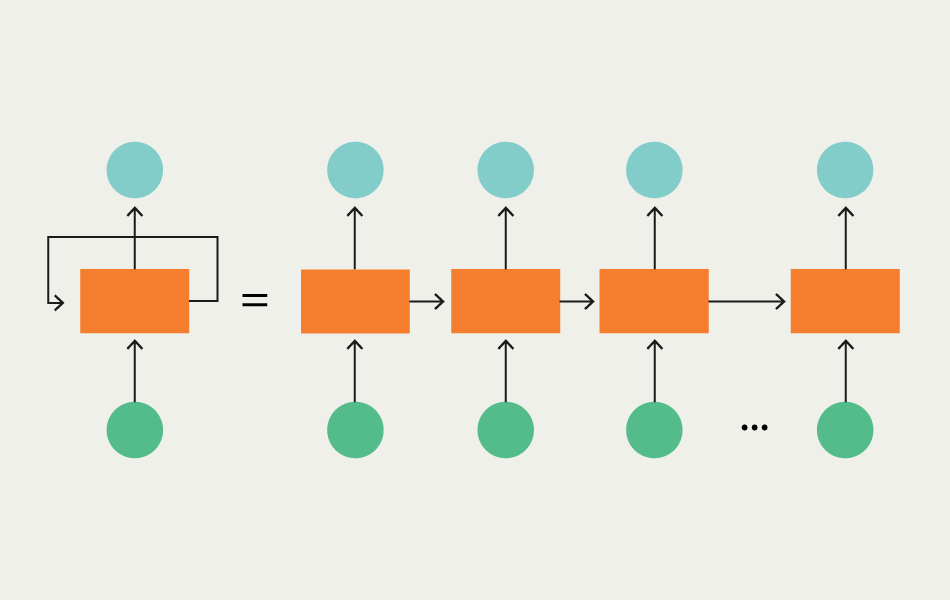
Recurrent Neural Networks (RNNs): Understanding Sequential Data
Recurrent neural networks (RNNs) are designed to handle sequential data, where the order of inputs is important. Unlike feedforward networks, RNNs have connections that form loops, allowing information to persist over time. This makes RNNs well-suited for tasks such as speech recognition, language translation, and time series prediction. However, traditional RNNs suffer from the vanishing gradient problem, which limits their ability to learn long-range dependencies.
Long Short-Term Memory (LSTM) Networks: Handling Time Series Data
Long short-term memory (LSTM) networks are a type of RNN designed to address the vanishing gradient problem. LSTM networks use specialized units, called memory cells, to store information over long periods. These cells are equipped with gating mechanisms that control the flow of information, allowing LSTMs to learn and remember long-range dependencies in sequential data. LSTMs have been instrumental in improving the performance of RNNs in tasks such as speech recognition and language modeling.
Generative Adversarial Networks (GANs): Creating Synthetic Data
Generative adversarial networks (GANs) are a class of neural networks that learn to generate synthetic data that is indistinguishable from real data. GANs consist of two networks: a generator and a discriminator. The generator learns to generate realistic data, while the discriminator learns to distinguish between real and fake data. Through adversarial training, GANs learn to produce high-quality synthetic data, with applications in image synthesis, data augmentation, and anomaly detection.
Transformer Networks: Revolutionizing Natural Language Processing
Transformer networks have revolutionized natural language processing (NLP) with their attention mechanism, which allows the model to focus on different parts of the input sequence when generating an output. Transformers have achieved state-of-the-art performance in tasks such as machine translation, language modeling, and text generation. Their self-attention mechanism enables them to capture long-range dependencies in text, making them more effective than traditional sequence-to-sequence models.
Understanding Neural Network Training and Optimization
Training a neural network involves adjusting the weights of the connections between neurons to minimize a loss function, which measures the difference between the predicted output and the actual output. This process, known as backpropagation, uses optimization algorithms such as gradient descent to update the weights iteratively. Hyperparameter tuning, regularization, and batch normalization are techniques used to improve the performance and generalization of neural networks.
Conclusion: The Future of Neural Network Architectures
Neural network architectures continue to evolve, driven by advancements in deep learning research and computational capabilities. Future architectures are likely to focus on improving efficiency, scalability, and interpretability, making neural networks more accessible and applicable to a wide range of real-world problems. As we continue to unlock the potential of neural networks, they will play an increasingly important role in shaping the future of artificial intelligence.